
9. A small review on Point Transformers
Point Transformer V1, V2 & V3.

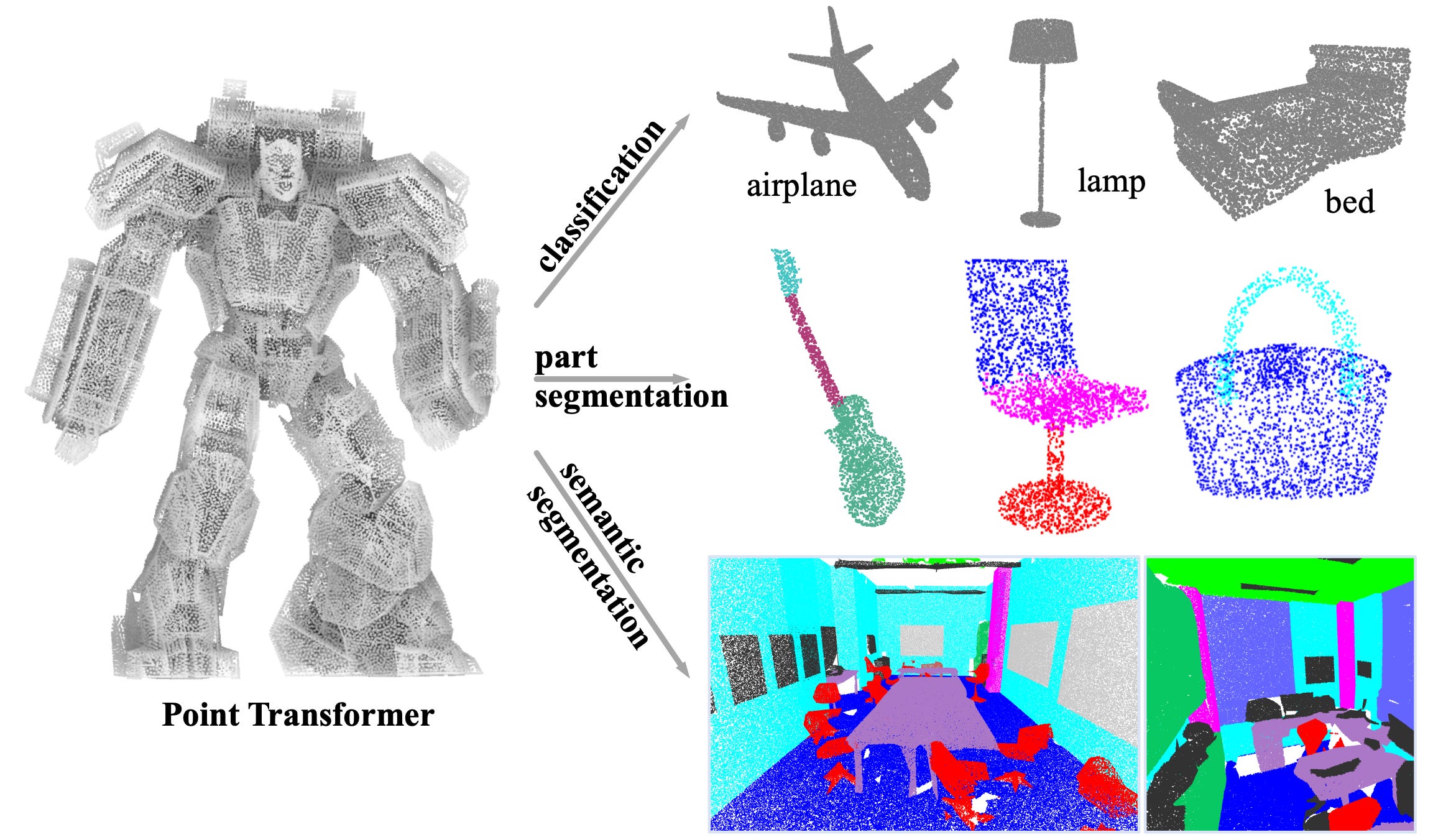
Introduction
Often data comes as a collection of points sampled in space, this is often the case for 3D computer vision and numerical simulations. This collections of points are called point clouds and, due to their lack of structure, to work with them provides several challenges.
Last week we talked about PointNets, a pioneering work on deep neural networks for point clouds. While they were extremely important to understand the challenges of working with unordered sets of points and to grasp their peculiar structure, nowadays these approaches have largely been replaced by attention-based models. Nowadays these techniques are completely replaced by Attention based models and this is what this blog will be about: We will go through the first line of work on transformers for point clouds, we will see that these models don’t use a standard “dot-product” attention but a novel “vector” attention and many other tricks.
Self-attention is natural on point clouds
Given an input X that is a sequence of N vectors of dimension d (X has shape Nxd), The self-attention operator of X is the following:
where the Softmax is applied row-wise and is defined as follows:
Self-attention is a natural operation on point-clouds because a point cloud is a set of coordinate–feature pairs and attention is a function on sets! By attention is a function on sets, I mean that if the input (actually its rows) is permuted, then the output is permuted in the same way (permutation-equivariance), therefore the attention is indipendent by the order of the input, as we show below, by taking a generic permutation P, then
since the Softmax is applied row-wise, then the permutation goes out of the Softmax and the P’s in the middle cancels out since the transpose of a permutation is its inverse.
Additionally, the attention is also independent of the size of the input sets, that is a necessary property to work with point clouds.
Point Transformer
Point Transformer was, probably, the first model to explore the use of self-attention in the context of point clouds. They called scalar attention the standard self-attention that we recalled in the previous section and the propose a novel mechanism called vector attention.
The name comes from the fact that the attention weights are vectors, rather than scalars as in standard attention. These weights are computed from pairwise differences between features, which are then passed through an MLP and normalized with a Softmax. The resulting attention vectors are applied pointwise to the sequence elements and then aggregated (typically by averaging) to produce the output at each location, in a way that is conceptually similar to standard scalar attention. The computation is as follows:
Crucially for point clouds, also the vector attention is a function on sets. To show that, let’s take a generic permutation P and plug it into the previous equation:
since permutations commute with subtraction by linearity, they also commute with the MLP, as it acts pointwise on the features. In fact, the MLP itself is a function on sets, since it is composed only of pointwise operations (i.e. 1x1 convolutions and pointwise nonlinearities). Finally, the pointwise product of two permuted vectors is simply the permutation of their pointwise product.
In practice, the MLP is has two layers with a ReLU nonlinearity in between and, for efficiency, they apply the vector attention on local windows computed by k-nearest neighbours (similar to Swin and Erwin transformers).
They also add a trainable positional embedding B, depending just on the relative positions
where the MLP used here has 2 layers with ReLU in between, as the one before, that is trained end-to-end with the other subnetworks. The positional encoding is then added to the attention scores as usual:
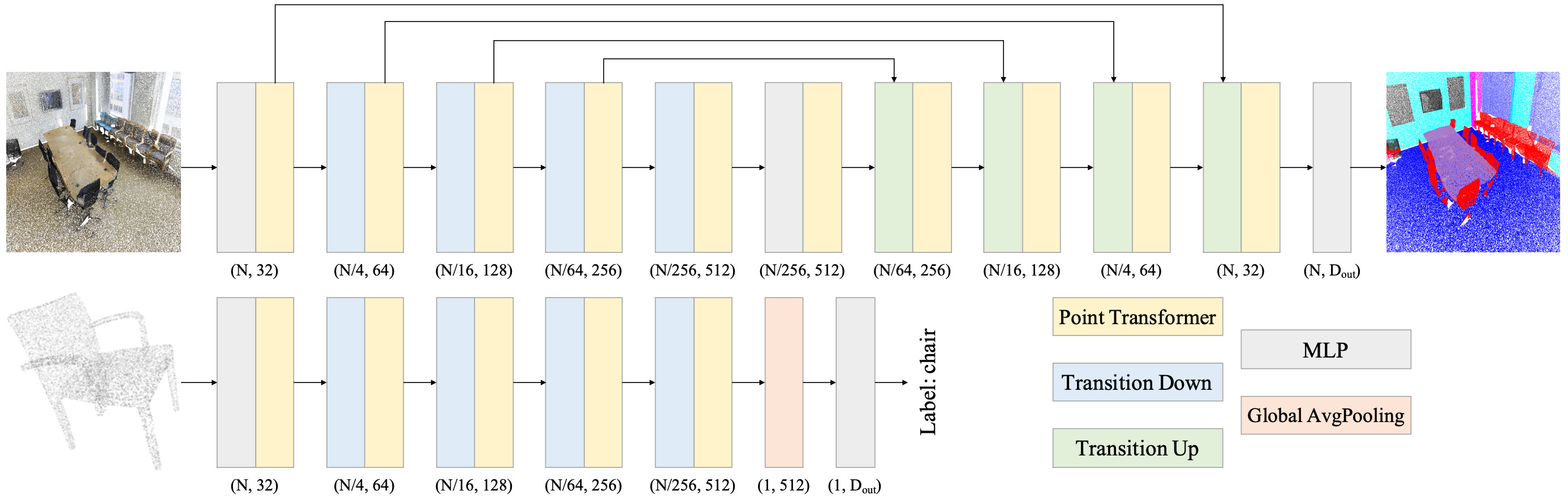
The Backbone. The network is based solely on point transformer layers, pointwise transformations, and pooling. In particular, it doesn’t use and convolutions for preprocessing or auxiliary branches. The feature encoder in point transformer networks that progressively downsample point sets. The model has a linear structure for classification and it’s U-shaped for dense prediction tasks.
Point Transformer V2
In the second version (PTv2), the model was upgraded on 3 crucial axis:
Grouped Vector Attention (GVA) for efficiency.
Improved positional encoding scheme.
Partition-based pooling strategy
Grouped Vector Attention (GVA).
In vector attention, as the network goes deeper and there are more feature encoding channels, the number of parameters for the weight encoding layer increases drastically. The large parameter size restricts the efficiency and generalization ability of the model.
In order to overcome the limitations of vector attention, PTv2 introduce the grouped vector attention that divides the channels of the value vector XW_v into g groups and each group shares the same vector attention, pretty much as in multi-head attention and grouped convolutions. The following is an illustration:
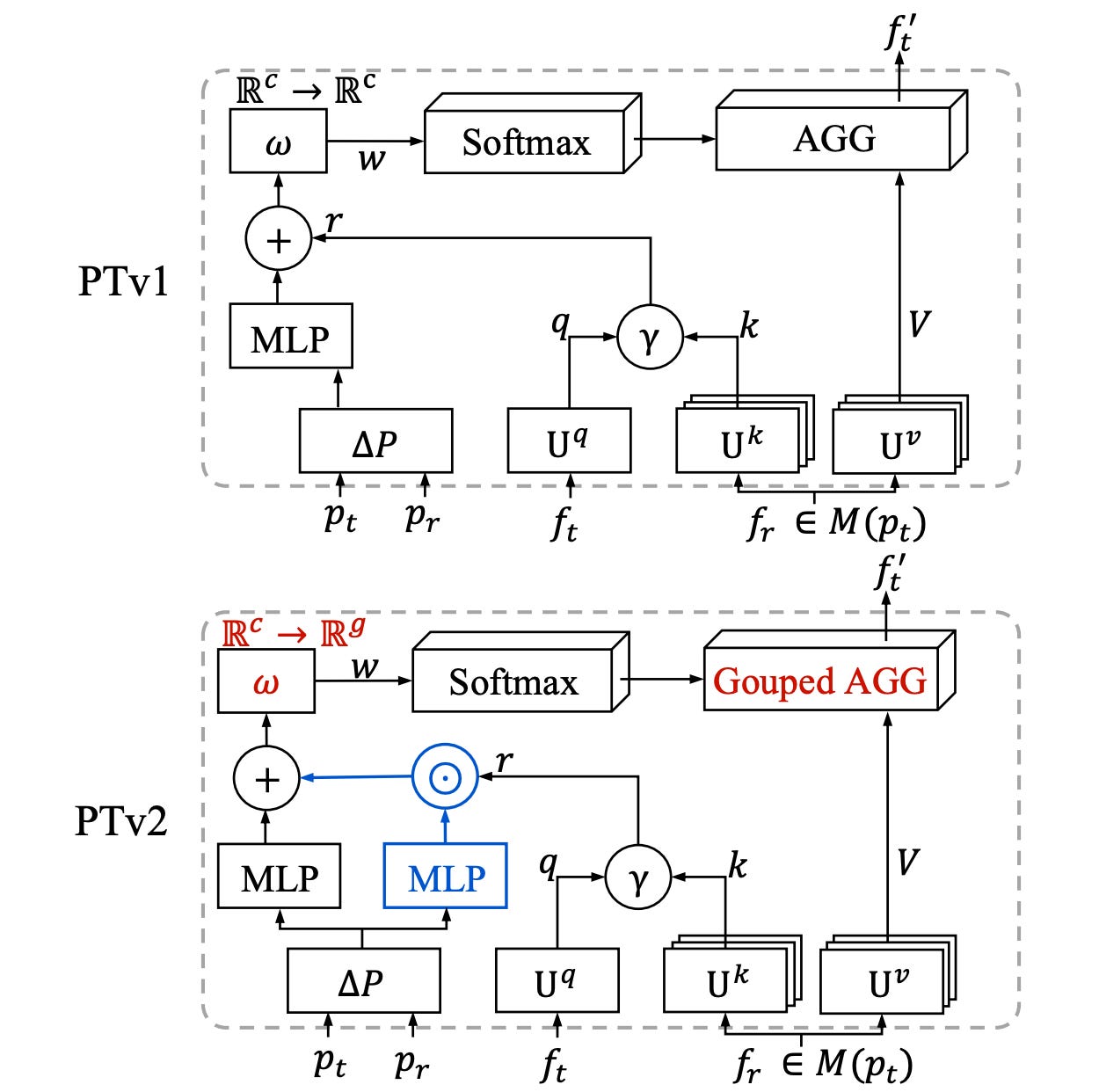
Interestingly, GVA is a generalization of the Multi-head self attention if the MLP used in the Vector Attention degenerates to a diagonal matrix. Different choice for the weight function (i.e. the MLP we were talking about) are showed in following figure:

Position encoding multiplier.
points in the 3D point cloud are unevenly distributed in a continuous Euclidean Metric space, making the spatial relationship in 3D point cloud much more complicated than 2D images. Therefore, in PTv2, they strengthen the position encoding with an additional multiplier to the relation vector,
which focuses on learning complex point cloud positional relations. Then it’s pointwise multiplied to the attention scores as follows:
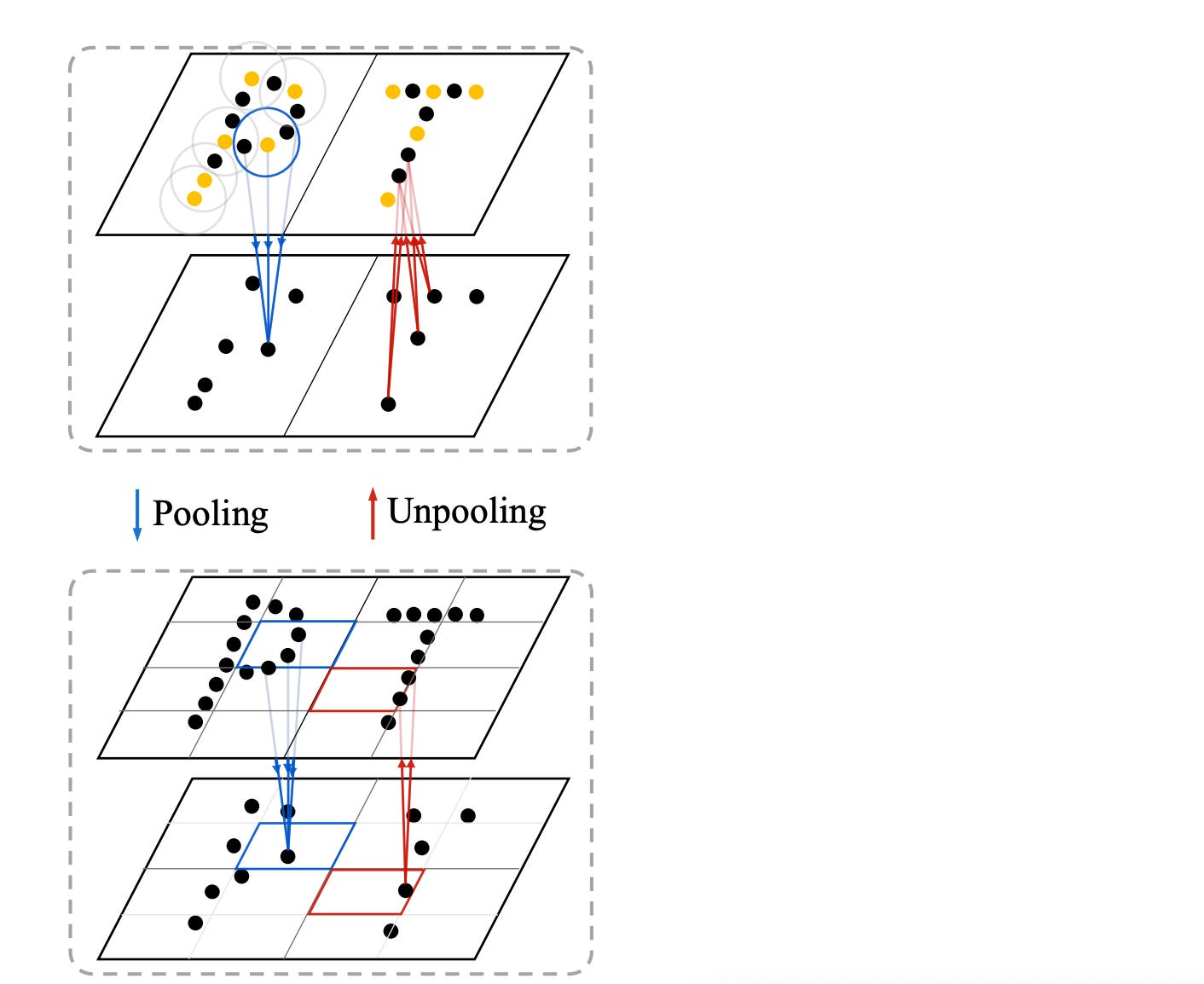
Partition based pooling.
Traditional sampling-based pooling procedures adopted by other point-based methods, such as Point Networks, use a combination of sampling and query methods. In these sampling-based pooling procedures, the query sets of points are not spatially-aligned since the information density and overlap among each query set are not controllable.
To address this problem they propose a more efficient and effective partition-based pooling approach: Given a point set, they partition it into non-overlapping subsets and they fusion each subset via max pooling. In the implementation, they use uniform grids for the partition. For the upooling they simply copy the updated features in all the point in each subset.
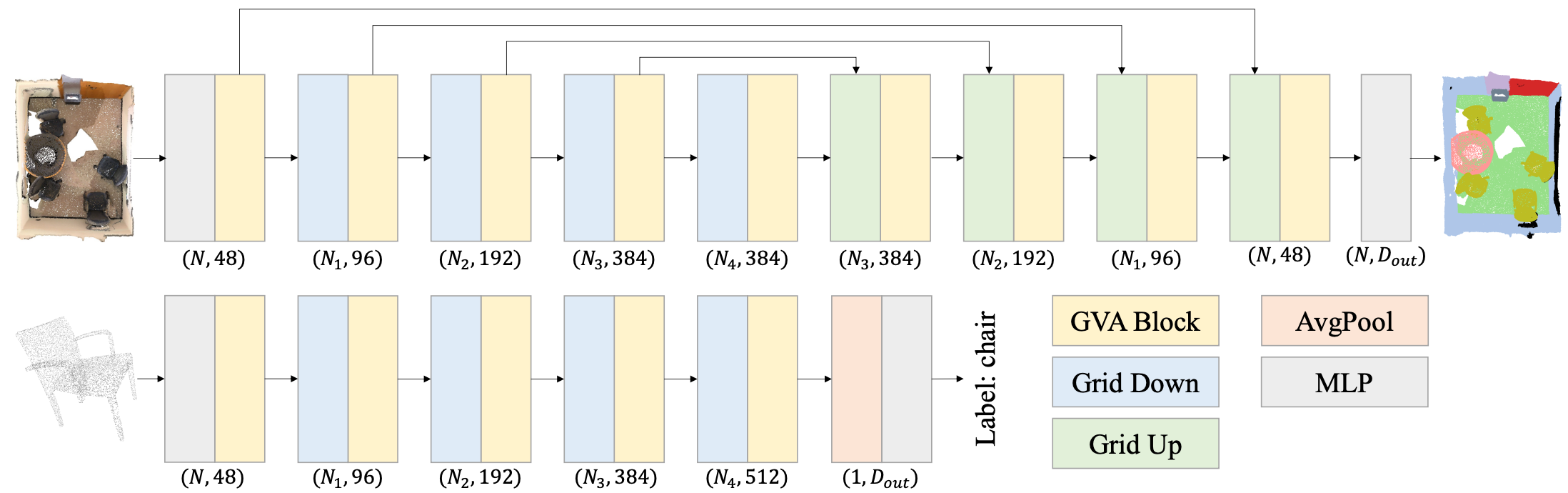
Backbone.
The backbone is similar to the one of the first version: it employs a residual U-Net structure:
Point Transformer V3
PTv3 focuses on overcoming the existing trade-offs between accuracy and efficiency within the context of point cloud processing prioritizing simplicity and efficiency over the accuracy of certain mechanisms that are minor to the overall performance after scaling, such as
replacing the precise neighbor search by KNN with an efficient serialized neighbour mapping of point clouds organized with specific patterns.
replacing attention patch interaction mechanisms, like shift-window with a sequential attention.
eliminating the reliance on relative positional encoding, which accounts for 26% of the forward time, in favor of a simpler prepositive sparse convolutional layer.
This principle enables significant scaling, expanding the receptive field from 16 to 1024 points while remaining efficient (a 3× increase in processing speed and a 10× improvement in memory efficiency compared with its predecessor, PTv2).
Serialization.
serialization-based methods structure point clouds by sorting them according to specific patterns, transforming unstructured, irregular point clouds into manageable sequences while preserving certain spatial proximity.
PTv3 choosed to give an ordering to the unstructured point clouds using space filling curves that are paths that pass through every point within a higher-dimensional discrete space and preserve spatial proximity to a certain extent.
Two are the most common space filling curves: the z-order curve and the Hilbert curve that are represented in the following visualization
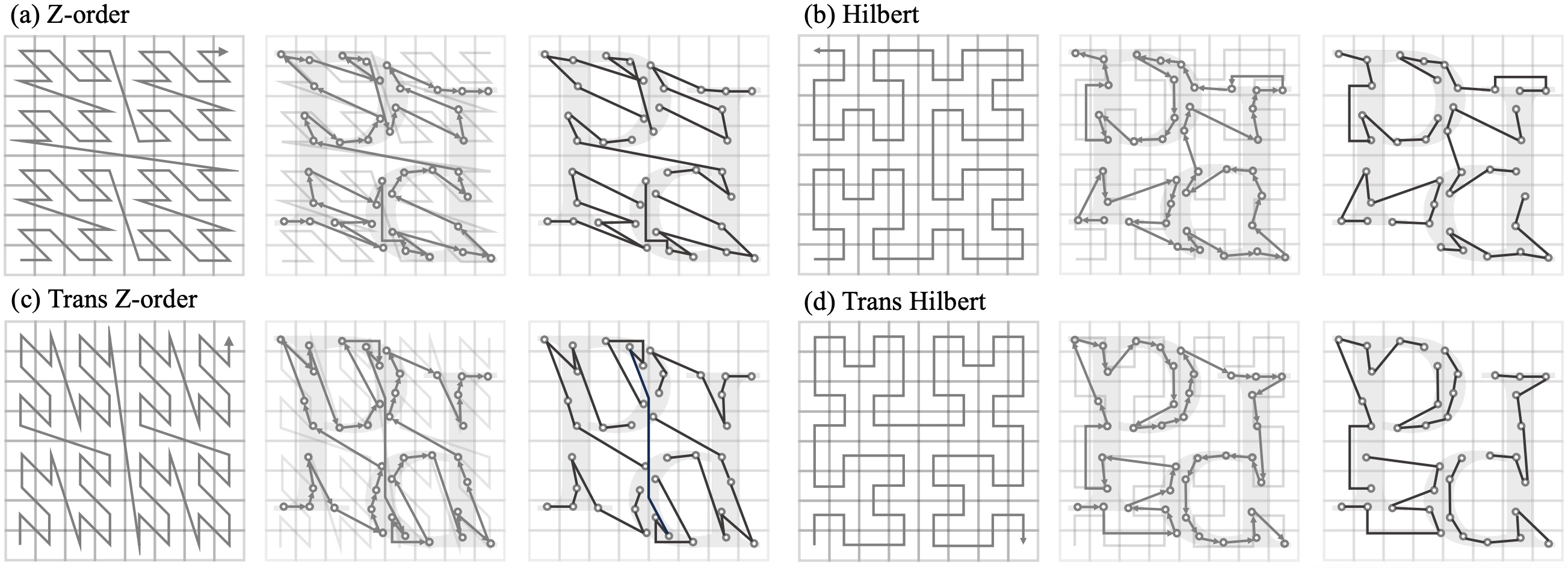
The Z-order curve is valued for its simplicity and ease of computation, whereas the Hilbert curve is known for its superior locality-preserving properties compared with Z-order curve.
Standard space-filling curves process the 3D space by following a sequential traversal along the x, y, and z axes, respectively. By altering the order of traversal, such as prioritizing the y-axis before the x-axis, PTv3 introduces reordered variants of standard space-filling curves, they denotes this variants in the figure with the prefix “Trans”.
While the serialization strategy temporarily yield a lower performance than some neighborhood construction strategies like KNN due to a reduction in precise spatial neighbor relationships, they demonstrate that any initial accuracy gaps can be effectively bridged by the scalability potential inherent in serialization.
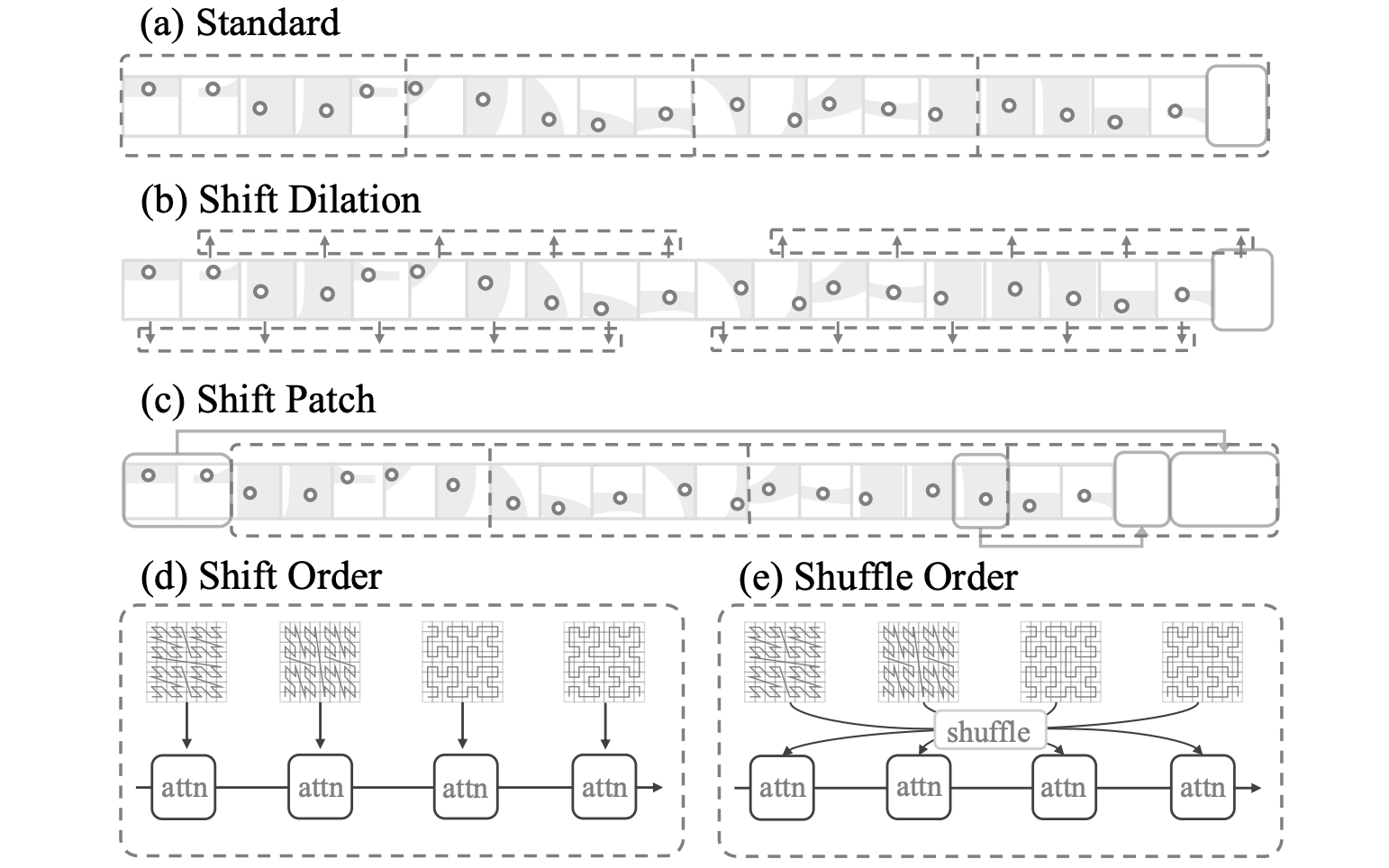
Serialized attention.
Since the input is linearized by a partition in curves, they apply on this a windowed attention, employing different serialization strategies
as illustrated here:
They also found that the relative positional encoding is very costly for point clouds, accounting for 26% of the forward time. Instead, they employ a variant of the conditional positional encoding (that use a multiscale cascade of convolutions) by prepending a sparse convolution layer with a skip connection before the attention layers.
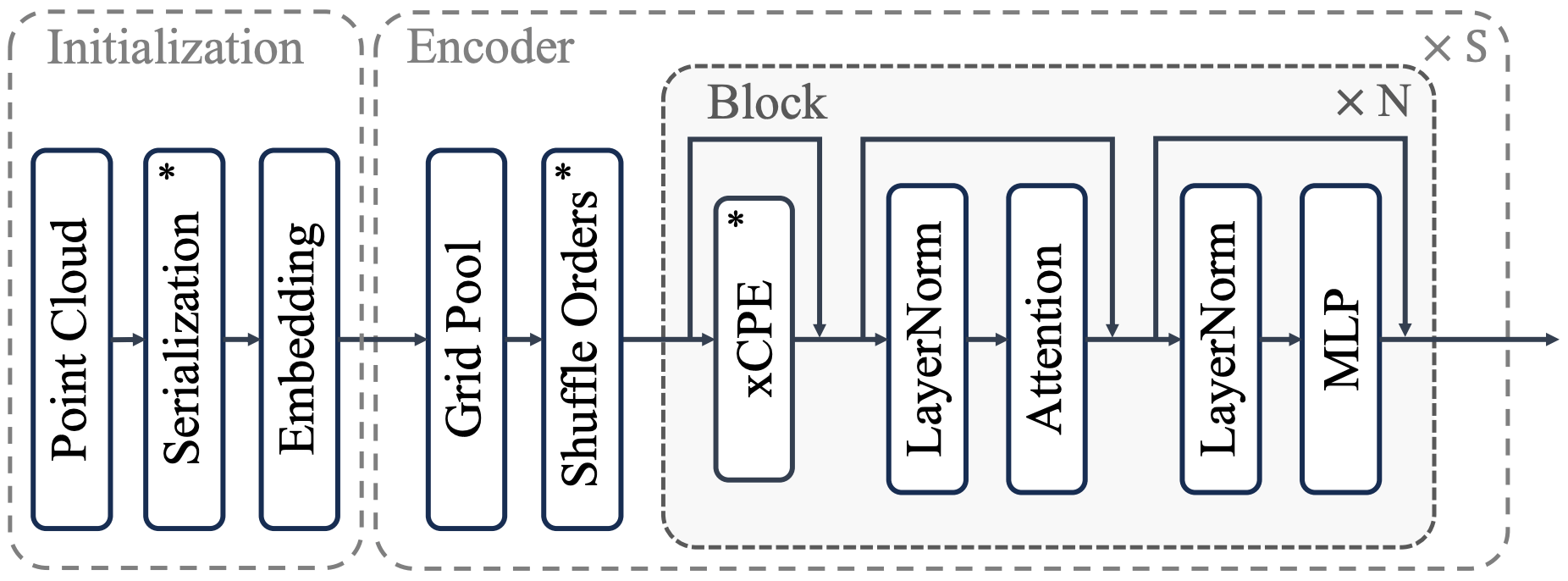
Backbone.
They adopt pre-norm residual blocks with Layer Norm as illustrated in the following visualization:
Conclusions
Attention is a natural operation on point clouds and Point Transformers performs really well, they are nowadays the state of the art for point cloud processing, from computer vision to Physics. I find particularly interesting that the third version improves on the previous by simplifying the model and loosing some nice properties (such as permutation-equivariance) in favor of an increased scaling that bridge and surpass the gap given by a worst modelization. As references I point to the original papers [1, 2, 3].